To understand Q-learning algorithm let's take an example of a maze environment that the agent needs to explore. Consider the below image.

In the image we have A: Agent , H-Hurdle , L: Lost, F: Food and G: Gold. The agent need to reach the Gold tile with shortest path in order to accomplish the game and the agent can only move one tile at a time.
If the agent steps on the lost tile Lost tile, the agent will die.
Rewards and Penalties for Agent for each state and action.
- The Agent will lose one point (-1) for each step, this is done , so that agent take shortest path.
- The agent will lose 50 (-50) points if the agent lends on Hurdle tile and the game will end.
- The agent gain one point (+1) if the agent lends on Food tile.
- The agent gain 50 point (+50) if the agent reaches on Gold tile and the game will end.
Now we know the problem, to get a good solution for the problem we need to train our agent in such a way that it can reach the Gold tile with shortest path.
For this we need to create a Q-table to note down the moves of agent's actions and agent's gain.
Q-table : Q-table is just a lookup table where we calculate the maximum expected future rewards for action at each state.
Let's try to understand it with the above example
There are four choices (actions) for the agent to move, if it is at a non-edge tile and three choices (actions) , if it is at edge tile.
Let's make a Q-table for agent's actions

Q-table is a iterative process, which is used to maximize expected future reward for agent for each state and action. We try to improve Q-table for each iteration.
How to decide values in Q-table for agent's each action ?
The value of Q-learning can be derived from the Bellman equation and the goal of this algorithm is to maximize the Q value.
Bellman equation (Q-function)

Q-values is calculated using above equation where st- states , at-action , γ-discount factor.
Q-learning algorithm process

Initialize the Q-table : We initialize Q table with value zero (0) in each cell. In Q table there are n numbers of column and m number of rows.
n= number of actions
m= number of states
Agent choose a path and perform action:
This step run under a loop until the time we stop the training. In this step we choose an action in the state based on Q value or Q table. But the problem is initially all values are zeros.
In this case we have a concept call exploration and exploitation. In simple terms exploration means exploring environment meaning new opprotunities and exploitation is we are using an opprotunity again and again.
For example going new restuarant at every weekend is exploration and going same restuarant at every weekend is exploitation.
Agent also work in same way during exploration time agent optimize Q value for maximum future reward.
In simple terms to short the path Agent try Epsilon greedy strategy concept. The rate of epsilon is high at starting as agent explore the environment and deacrese as agent start exploiting environment.
Epsilon greedy strategy : Epsilon-Greedy is a simple method to balance exploration and exploitation by choosing between exploration and exploitation randomly.
Evaluation: In this step we actually first measure the reward and then evaluate Q function.
This process is repeated again and again until the learning is stopped. In this way the Q-Table is been updated and the Q function is maximized.
Q-Learning Algorithm in conclusion:
Q-learning is a value based reinforcement learning algorithm meaning a off policy reinforcement learning algorithm which is used to find a optimal action selection policy using Q-function and Q-table where our goal is to maximize Q-function by iteratively updating Q-table in bellman equation.
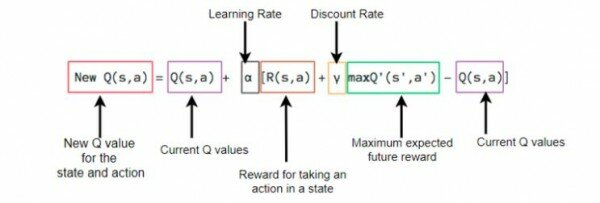
Q(state, action) returns the expected future reward of that action at that state.



